Case1-scraping OSCHINA site
Introduction
To demonstrate the HTTP request functionality of Hutool-http, this example uses the open source information section of oschina (oschina.net) as a simple demo.
Getting Started
Analyzing the Page
- Open the homepage of oschina (oschina.net) and find the prominent open source information module. Click on “More” to open the “Open Source Information” section.
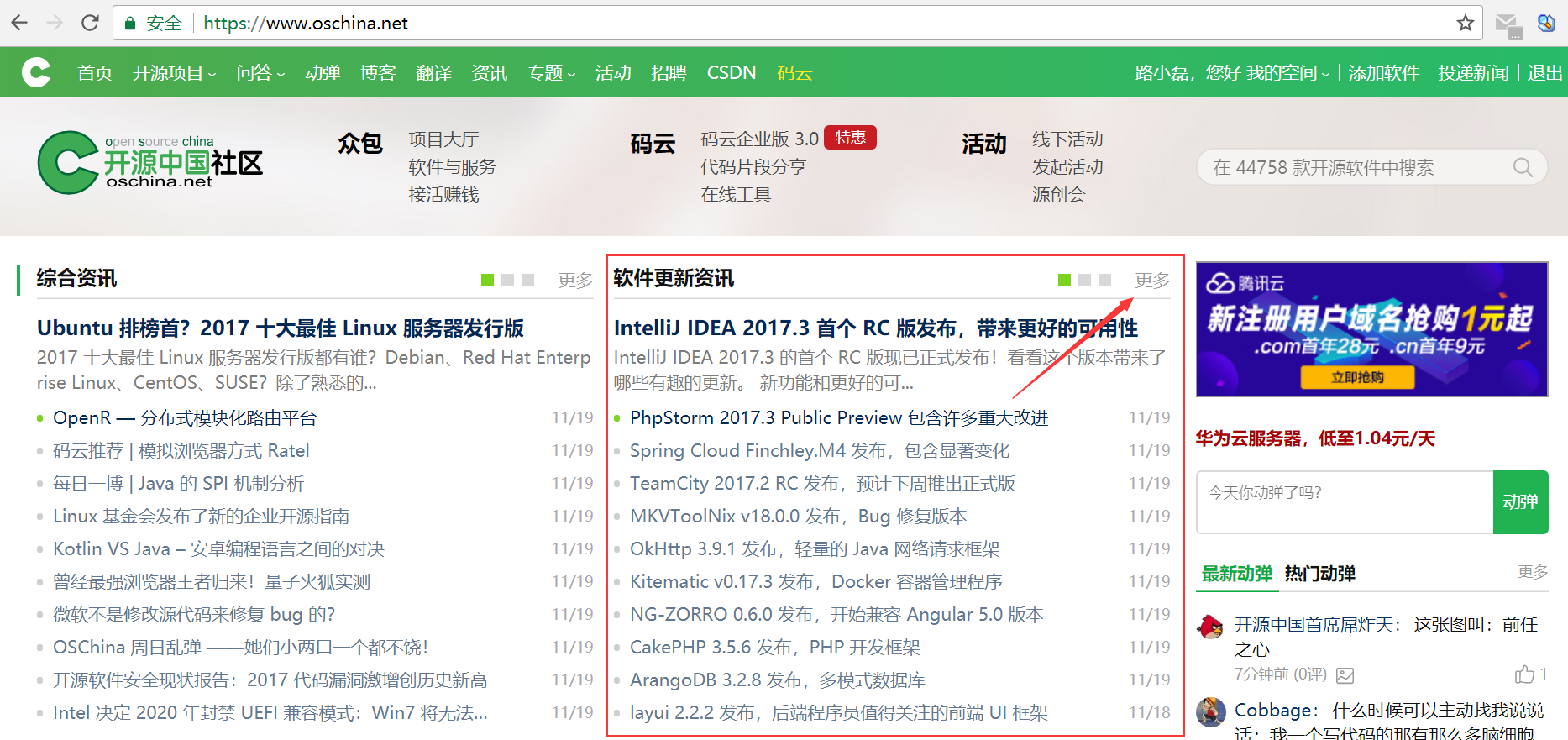
- Open the F12 debugger by pressing the F12 key on your keyboard to open Chrome’s debugger. Click on the “Network” tab and then click on “All News” on the page.
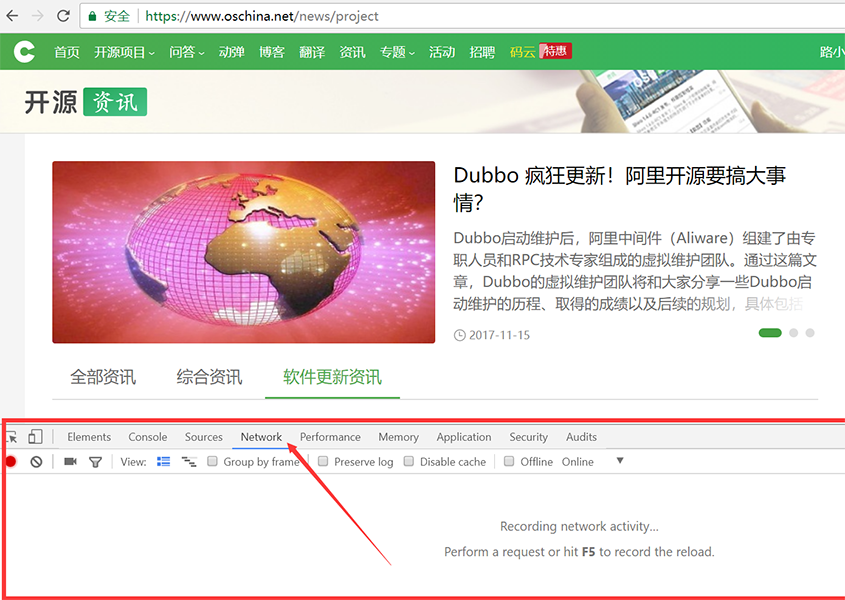
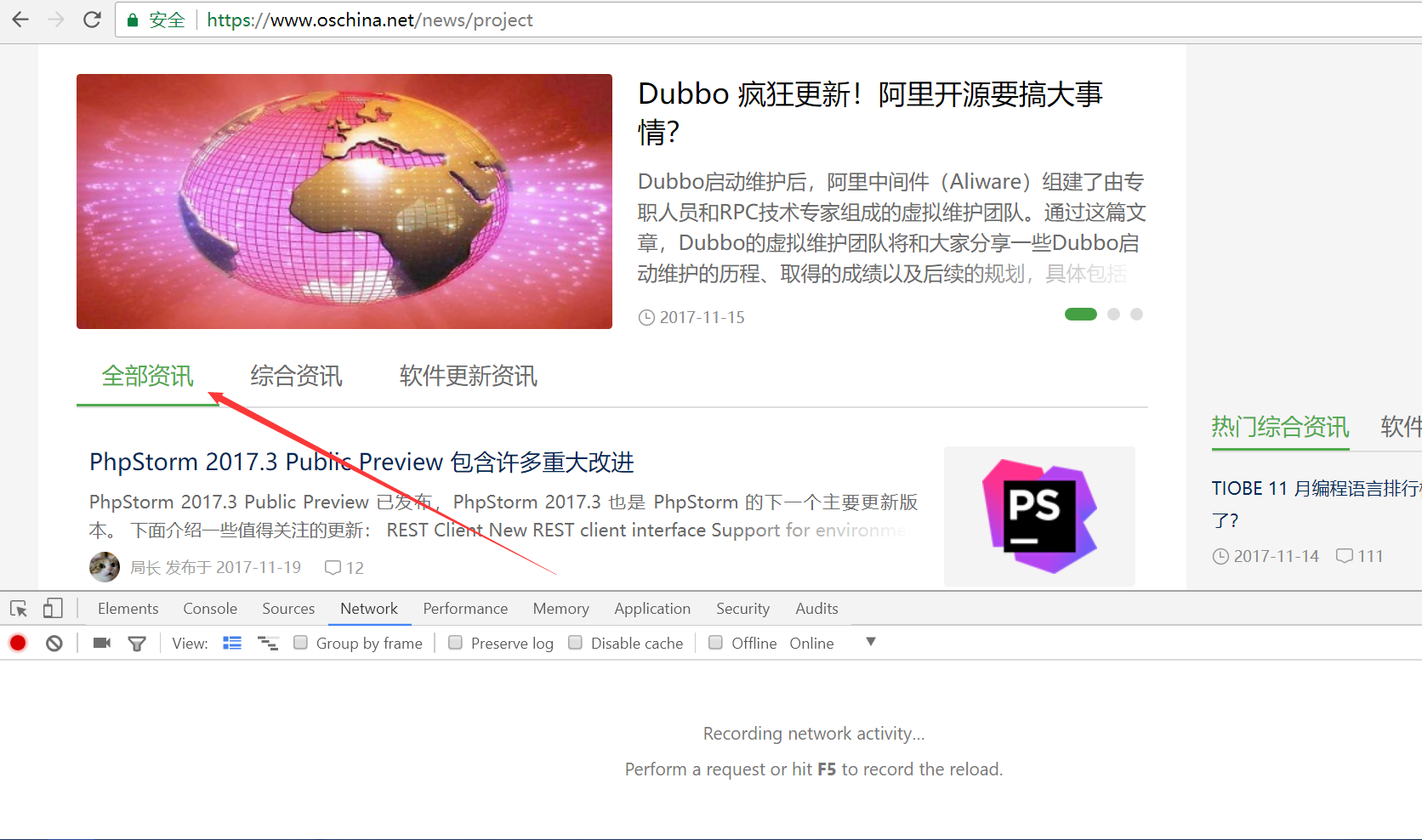
- Since the list page of oschina is paginated by scrolling down, scrolling to the bottom will trigger the loading of the second page. Scroll to the bottom and observe if there is a new request in the debugger. As shown in the figure, we find that the second request is for the second page of the list.
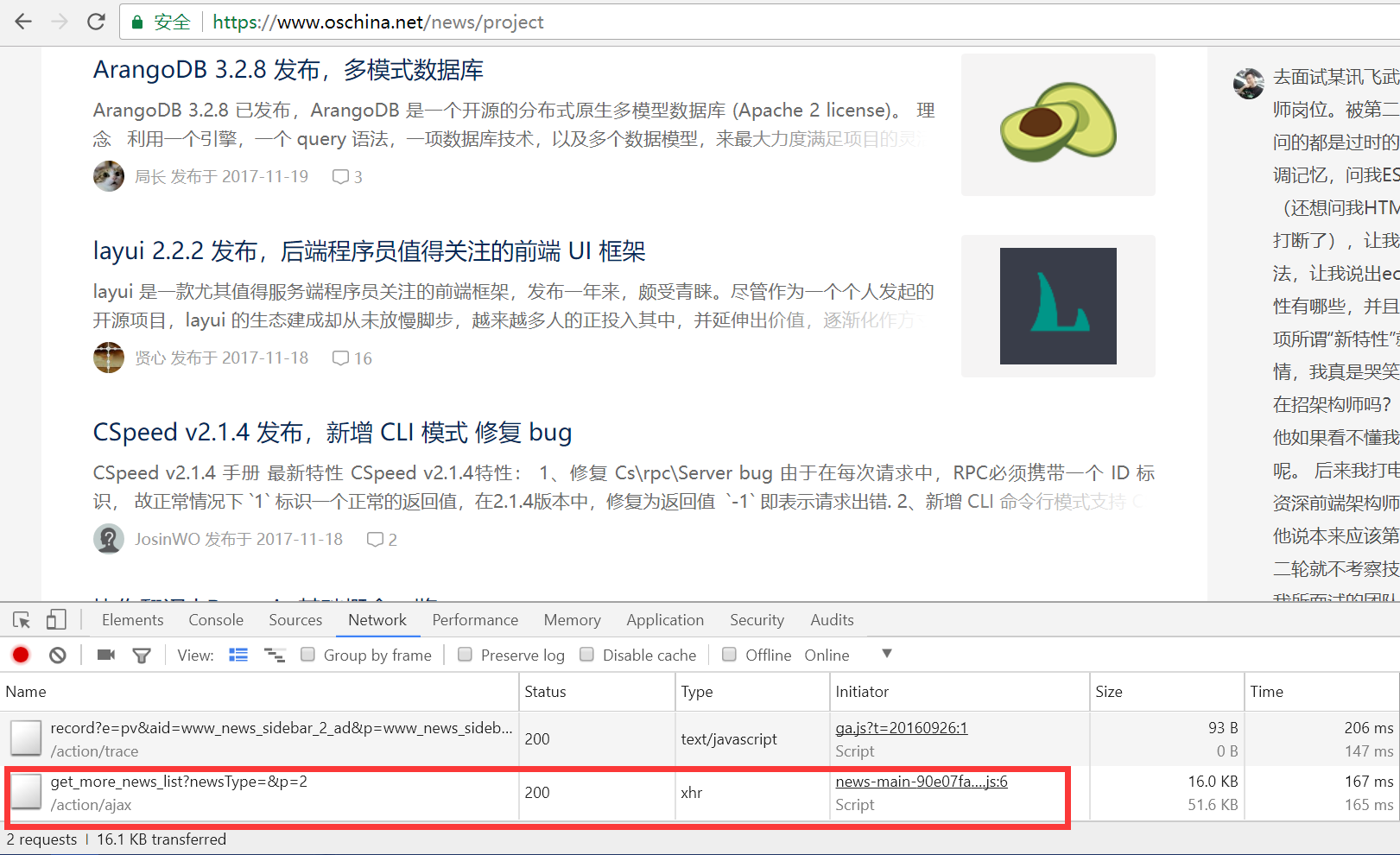
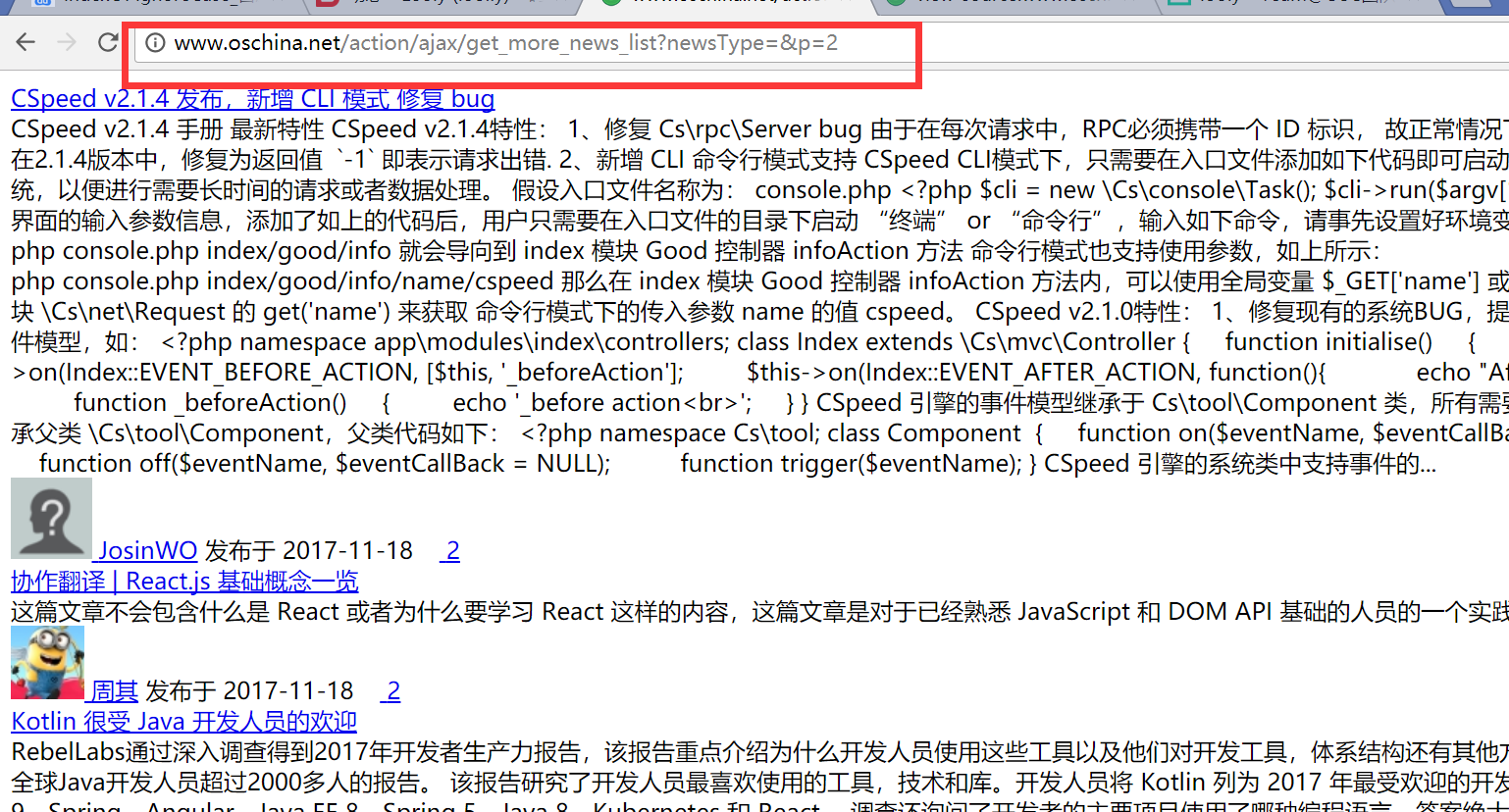
- We open this request URL and can see the pure content. The red box indicates the address of the second page of content, and it is clear that the “p” parameter represents the page number.
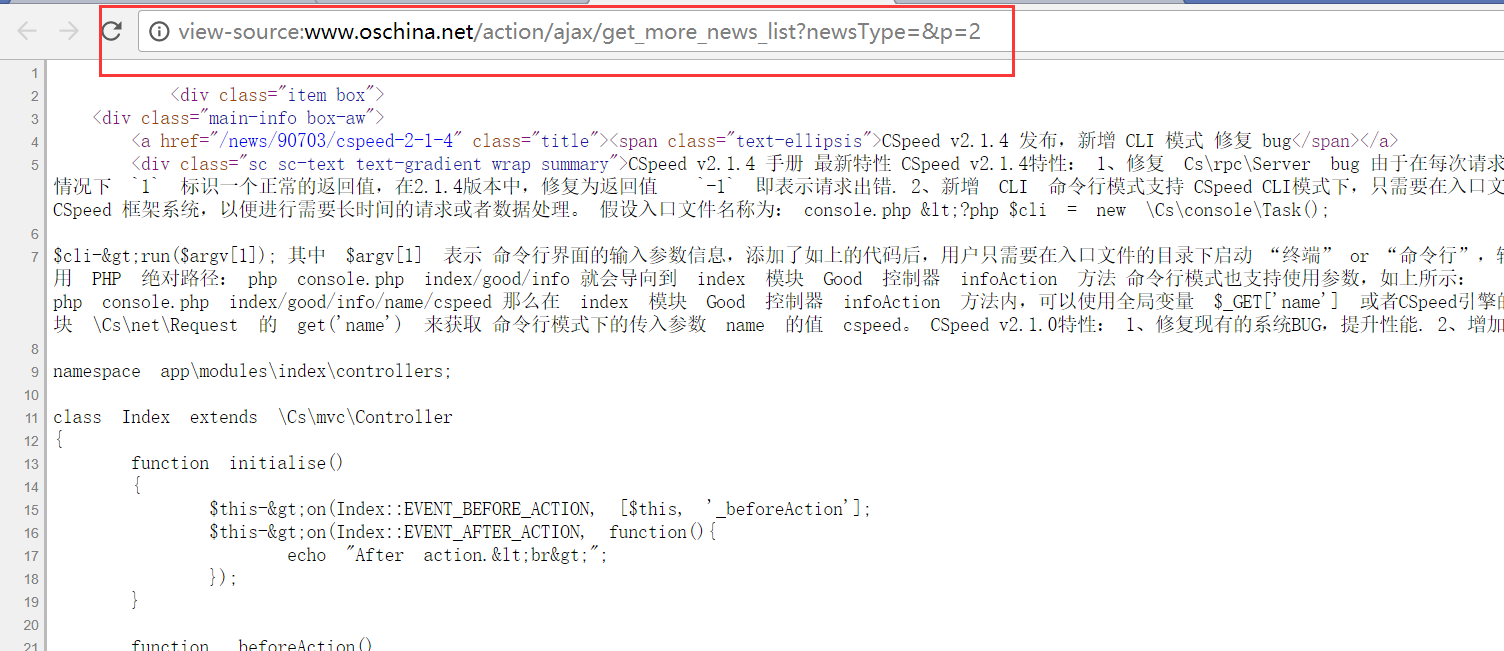
- We right-click and view the source code to see the source code.
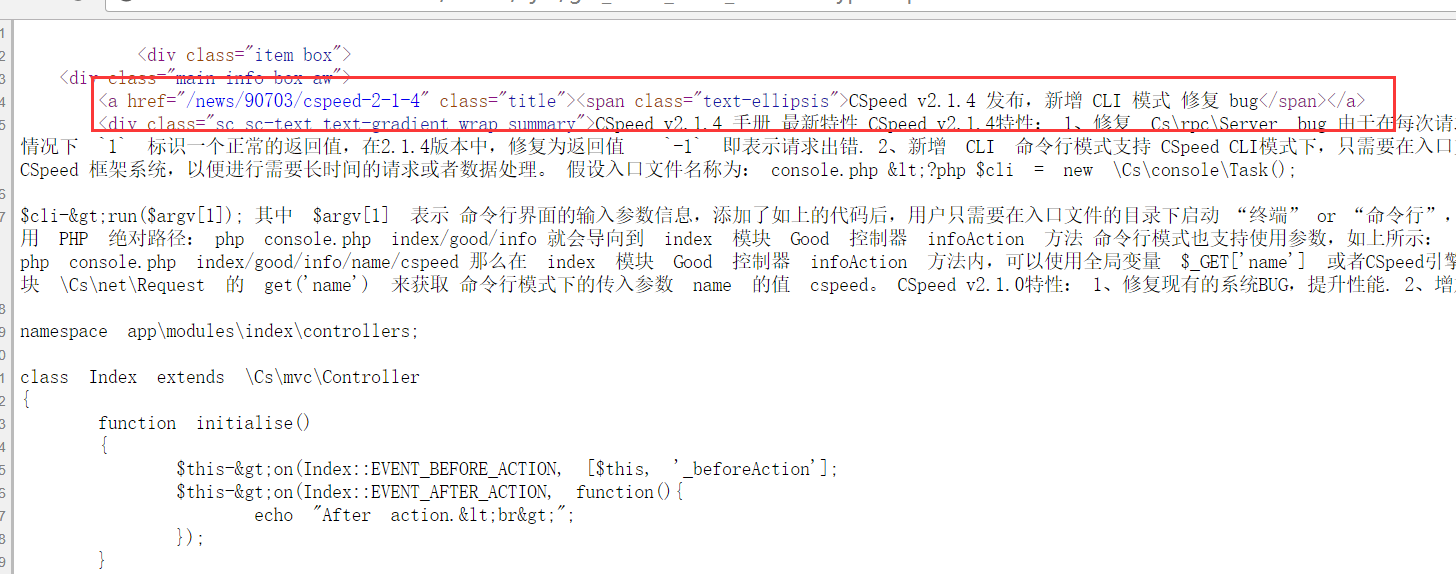
- Find the HTML source code of the title section and search for the HTML part that surrounds this title to see if we can locate the title.
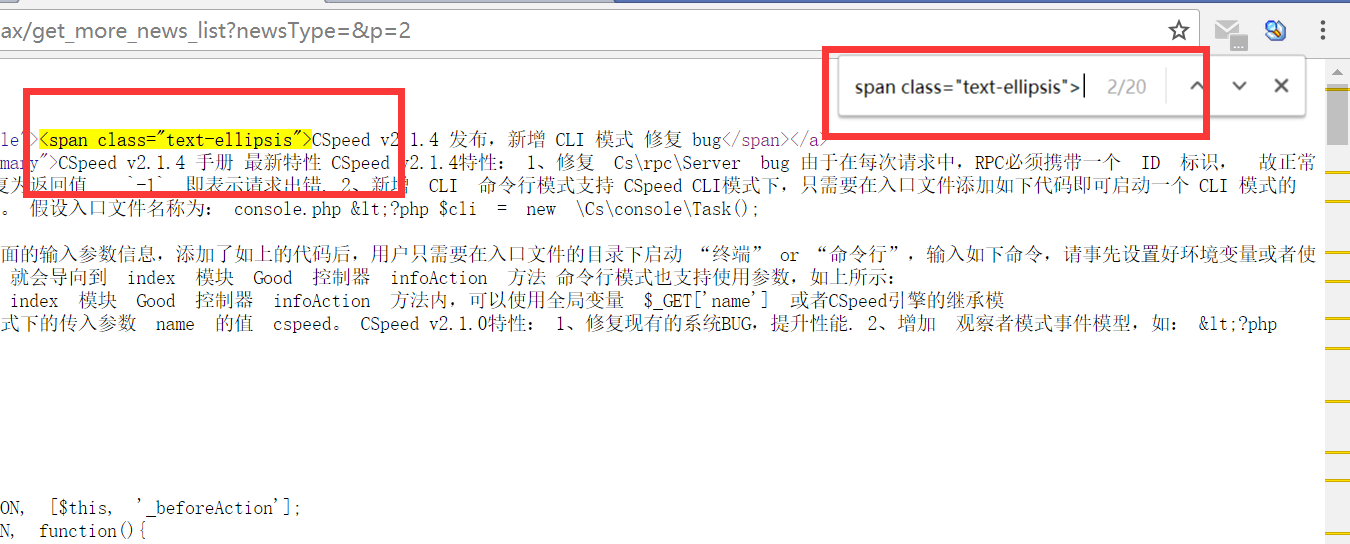
Now that we have analyzed the page and obtained the address of the list page and the relevant characters that can locate the title (which will be used later with regular expressions to extract the title), we can begin using Hutool to code.
Simulating HTTP Requests to Crawl Pages
Using Hutool-http with ReUtil to request and extract page content is very simple, as shown in the following code:
// Request list page content
String listContent = HttpUtil.get("https://www.oschina.net/action/ajax/get_more_news_list?newsType=&p=2");
// Use regular expressions to find all titles
List<String> titles = ReUtil.findAll("<span class=\"text-ellipsis\">(.*?)</span>", listContent, 1);
for (String title : titles) {
// Print the title
Console.log(title);
}The crawling result is as follows:
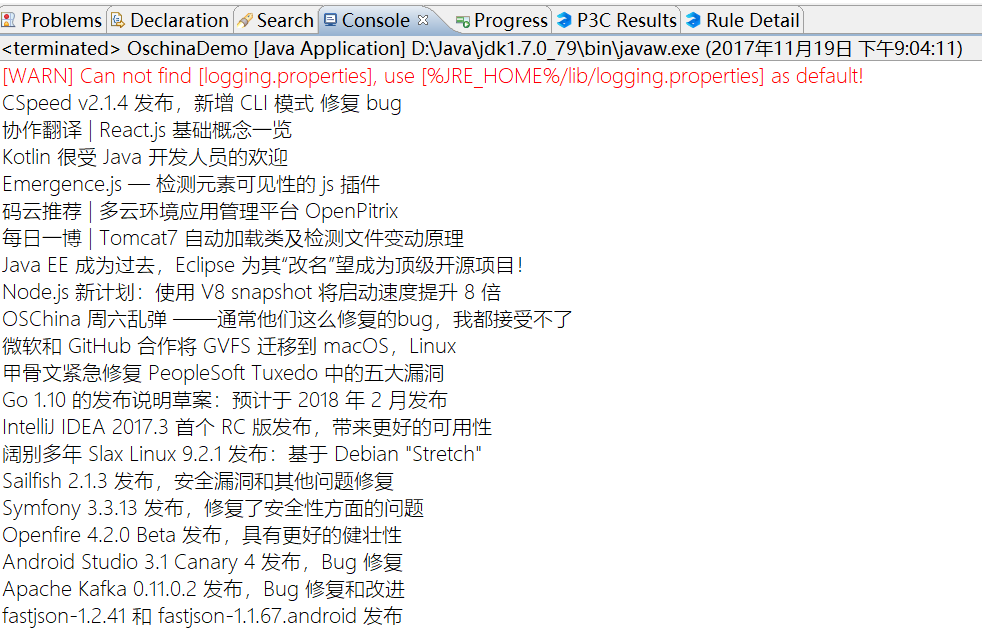 In fact, the core is just the first two lines of code. The first line requests the page content, and the second line uses regular expressions to locate all title lines and extract the title part. Here I will explain the regular expression part: The ReUtil.findAll method is used to find all parts that match the regular expression, where the second parameter 1 indicates extracting the content of the first parenthesis (group), and 0 indicates extracting all content that matches the regular expression. This method can be found in the core module’s ReUtil section for more details.(.*?)This regular expression is what we obtained after analyzing the page source code, where
In fact, the core is just the first two lines of code. The first line requests the page content, and the second line uses regular expressions to locate all title lines and extract the title part. Here I will explain the regular expression part: The ReUtil.findAll method is used to find all parts that match the regular expression, where the second parameter 1 indicates extracting the content of the first parenthesis (group), and 0 indicates extracting all content that matches the regular expression. This method can be found in the core module’s ReUtil section for more details.(.*?)This regular expression is what we obtained after analyzing the page source code, where (.*?) represents the content we need, . represents any character, * represents 0 or more occurrences, and ? represents the shortest possible match. The whole regular expression means to match any characters that start with <span class="text-ellipsis"> and end with </span>, with the shortest possible length for the middle part. The role of ? is to limit the range to the minimum, otherwise </span> may match further down the line.
For more information on regular expressions, you can refer to my blog post: Regex Quick Reference (in Chinese).
Conclusion
It has to be said that web scraping itself is not difficult, especially when combined with Hutool, which makes the task even simpler and faster. The difficulty lies in analyzing the page and locating the content we need.
The actual process of web scraping can be divided into four parts:
- Finding the list page (many websites do not have a general list page)
- Requesting the list page to obtain the address of the detail page
- Requesting the detail page and using regular expressions to match the content we need
- Storing the content in a database or saving it as a file
During the scraping process, we may encounter various problems, including but not limited to:
- IP blocking
- Specific requirements for request headers
- Specific requirements for cookies
- Captcha
There are solutions to these problems, which need to be analyzed and solved in specific development contexts.
I hope this example can inspire you and provide more and better suggestions for Hutool.